It was easy! It was cheap! It was rubbish!
It seems everybody wants to carry out their own media content analysis on welfare these days. Unfortunately nobody seems to want to put in the work needed if you want to avoid coming to silly conclusions. Yesterday I wrote about exaggerated claims circulating on the left-wing twittersphere about an implausible rise in the use of the word 'scrounger' http://lartsocial.org/press . Today, the right has hit back with an even sillier claim: the Guardian and Independent are the titles that stigmatise benefit claimants most. 'Guido has been crunching the numbers, and it turns out it is none other than the Guardian that uses the word most, followed by the Indy, where Owen [Jones] has a column.' http://order-order.com/2013/05/02/guardian-uses-scrounger-more-than-any-...
I'll let you savour the phrase ''Guido has been crunching the numbers' for a moment before we get down to business.
OK, where to start? Counting words using the internal search engines of media sites (which is what they've done) is obviously no way to assess coverage, as (a) there is no reason to believe that all websites are equally representative of the content of titles (b) articles get deleted from websites but not print editions and (c) some titles have much more developed online content than others, notably the Guardian. It's not the same as using a service like LexisNexis which archives the content of print editions. Counting a single word is pointless as it only tells you that the word has occurred, while saying nothing about how it was used. Is Polly Toynbee's use of the word 'scrounger' going to be comparable to Rod Liddle's? No.That's why most serious content analysis involves actually, y'know, reading stuff?
For our analysis http://www.turn2us.org.uk/PDF/Benefits%20Stigma%20in%20Britain.pdf we combined word-counting (on a set of 6,000 articles) with manual coding (of a 20% sample of the articles). We didn't just count words: using a custom-built database we were able to look at co-occurrences of different vocabularies in the same article. This was pretty time consuming, but it beats passing off the output of a couple of hours of timewasting on media search engines as serious analysis.
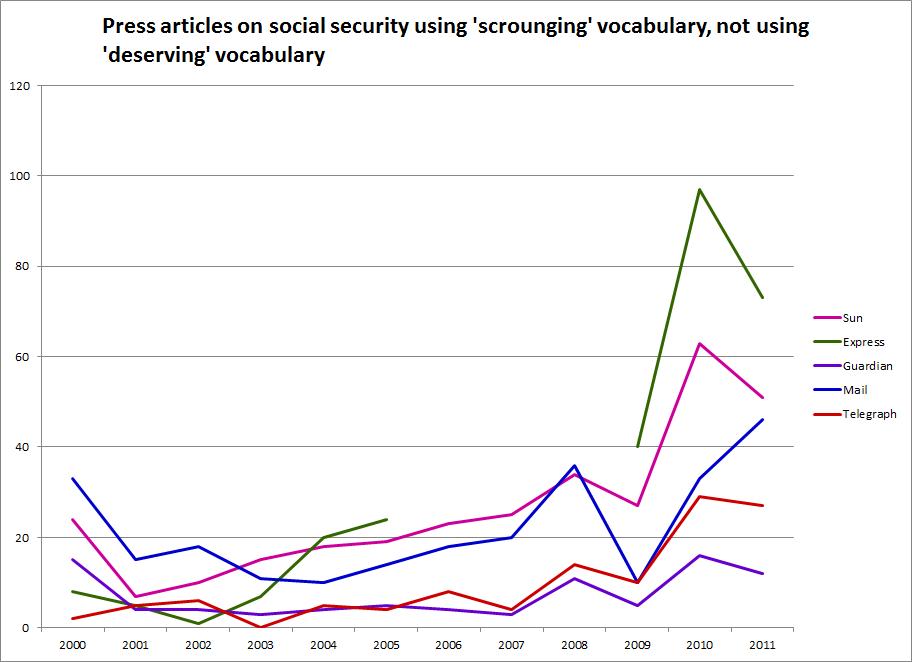
Here's a new chart, based only on word-counting, which gives a somewhat more rounded picture of how the language used by different titles compares than Guido's number crunching. What we've done is to count articles which use 'scrounger' and related terms conveying the general idea of people getting something for nothing, but which /don't/ use vocabulary associated with a more sympathetic view of claimants- terms like 'disabled' or 'hard-pressed'. I've left a number of titles out to keep the chart comprehensible, so we're looking at the Express (the broken green line- there's a break in the data mid-decade), Sun (pink), Guardian (purple), Telegraph (red) and the Mail (deepest blue).
The Express and Sun are clearly the most prone to print articles which use the language of 'scrounging' without tempering this with any language reflecting the 'deservingness' of claimants. And along with the Mail, they seem to have stepped up to the mark when the coalition was elected, increasing their output of negative articles at a much faster rate than other titles. The two broadsheets are at the bottom. The Telegraph shows an upward trend from 2009 to 2010, but nothing comparable to that for the Mail. The Guardian shows a much more modest rise. As for the notion that the Guardian is the most negative, it turns out to be just as dumb as you probably thought it was.
What should we make of all this? Not too much, I 'd suggest. The virulence of the Sun, Express and Mail on benefits is hardly news, except apparently to Guido Fawkes. The widespread sense that things got a lot worse after the 2010 election isn't misplaced, although over the longer term, going back to the late 1990's, the post-election period isn't unprecedented. But again, we knew this already. The main lesson may be about the risk that the increasing availability of data for 'number-crunching' from media sites leads people to think they can run off analysis without bothering to check the quality of the data, upgrade their analytic skills or bother learning anything about the subject.
If you're wondering about the headline, by the way, this: http://en.wikipedia.org/wiki/Desperate_Bicycles